Data scaling for navigation in unknown environments
IEEE Robotics and Automation Letters (RA-L)
Lauri Suomela 1 · Naoki Takahata 2 · Sasanka Kuruppu Arachchige 1
Harry Edelman 3 · Joni-Kristian Kämäräinen 1
1 Tampere University · 2 Tohoku University · 3 Turku University of Applied Sciences

Generalization of imitation-learned navigation policies to environments unseen in training remains a major challenge. We address this by conducting the first large-scale study of how data quantity and data diversity affect real-world generalization in end-to-end, map-free visual navigation. Using a curated 4,565-hour crowd-sourced dataset collected across 161 locations in 35 countries, we train policies for point goal navigation and evaluate their closed-loop control performance on sidewalk robots operating in four countries, covering 125 km of autonomous driving.
Our results show that large-scale training data enables zero-shot navigation in unknown environments, approaching the performance of policies trained with environment-specific demonstrations. Critically, we find that data diversity is far more important than data quantity. Doubling the number of geographical locations in a training set decreases navigation errors by ~15%, while performance benefit from adding data from existing locations saturates with very little data. We also observe that, with noisy crowd-sourced data, simple regression-based models outperform generative and sequence-based architectures.
Training data
We extract clean demonstrations from a raw 8,000 hour crowd-sourced dataset, and cluster the resulting 4,565 hours of navigation data into 161 distinct locations around the world. The locations span 35 countries and diverse environments, including urban, suburban, park, campus, and rural settings.
Test locations




We test our policies in 4 distinct locations around the world. These locations were not included in the training data, allowing us to evaluate the generalization capabilities of the navigation policies.
Policy deployment examples
The policies were deployed on the Earth Rover Zero robots. The robots streamed sensor observations to a remote desktop machine running policy inference, and the computed control commands were sent back to the robots over a 4G connection.
Data scaling results
We trained policies with subsets of the total dataset, varying both the number of training locations and the amount of training data per location.


The results indicate that navigation performance scales well with the number of training locations, while benefit from increasing the amount of data per location saturates early, below the range we considered in our experiments. This highlights the importance of data diversity for generalization in visual navigation.

Fitting a model $Y = \beta \cdot X^{\alpha}$ to the results, we find that the navigation Failure Rate = 1 - Success Rate follows the number of training locations with a power law relationship. Substituting the coefficients from the left panel, doubling the number of locations decreases failures by $1-\frac{Y(2X)}{Y(X)}=1-2^{-0.229}\approx15\%$.
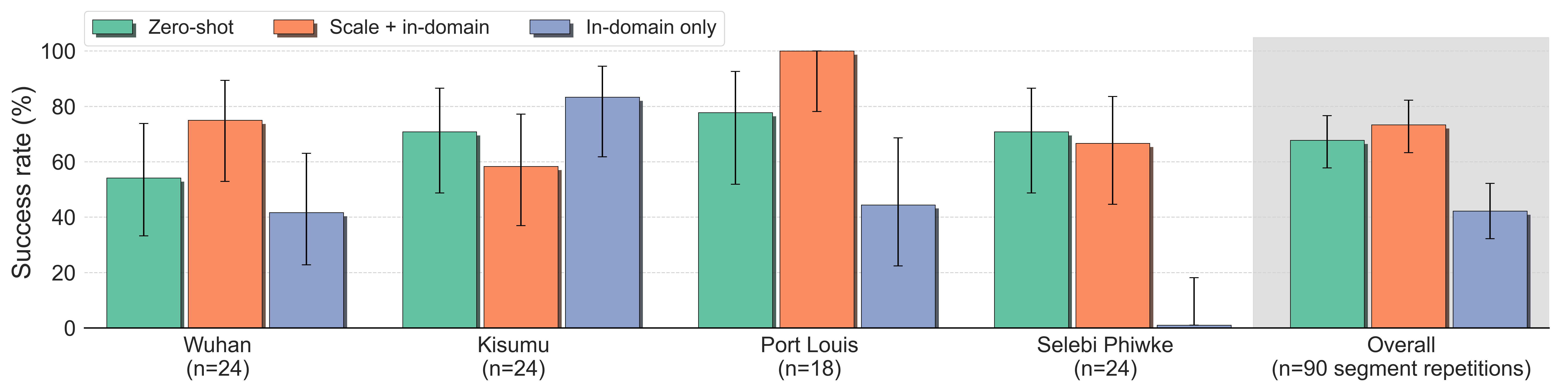
Training with the full dataset
We also experimented with training on the full dataset. We compared the policy trained with the full train set (Zero-Shot) to a policy trained with both the full train set and additional in-domain data from the test locations (Scale + in-domain), and environment-specific policies trained only with data from each test location (In-domain only).
Full runs
The videos demonstrate one complete navigation run from each test location.
BibTex
@article{suomela2026data,
title={Data Scaling for Navigation in Unknown Environments},
author={Suomela, Lauri and Takahata, Naoki and Kuruppu Arachchige, Sasanka and Edelman, Harry and Kämäräinen, Joni-Kristian},
journal={IEEE Robotics and Automation Letters},
year={2026},
volume={},
number={},
pages={1-8},
doi={10.1109/LRA.2026.3677718},
}